神经网络优化核心:鞍点而非局部极小值
1 前言
当模型在训练集上损失居高不下,且增加模型复杂度后损失未降反升时,问题通常不在于模型 bias,而在于优化过程本身——梯度下降易在高维损失景观中被困于鞍点,本文结合 Hessian 矩阵与实验证据,梳理相关核心结论。
2 梯度下降收敛停滞的关键原因
梯度下降过程中,当梯度∇L (θ)=0 时,损失函数值不再变化,优化陷入停滞。造成这一现象的原因并非仅为局部最小值点,还可能是鞍点,两者核心区别如下:
-
局部最小值点(local minimum point):梯度为 0,且任意方向移动损失均增大,优化达到局部最优;
-
鞍点(saddle point):梯度为 0,存在一对正交方向,沿其中一个方向移动损失增大,沿另一个方向移动损失减小,并非最优解,却会导致梯度下降停滞。
综上,局部最小值点与鞍点的梯度均为 0,这两类梯度为 0 的点统称为驻点。
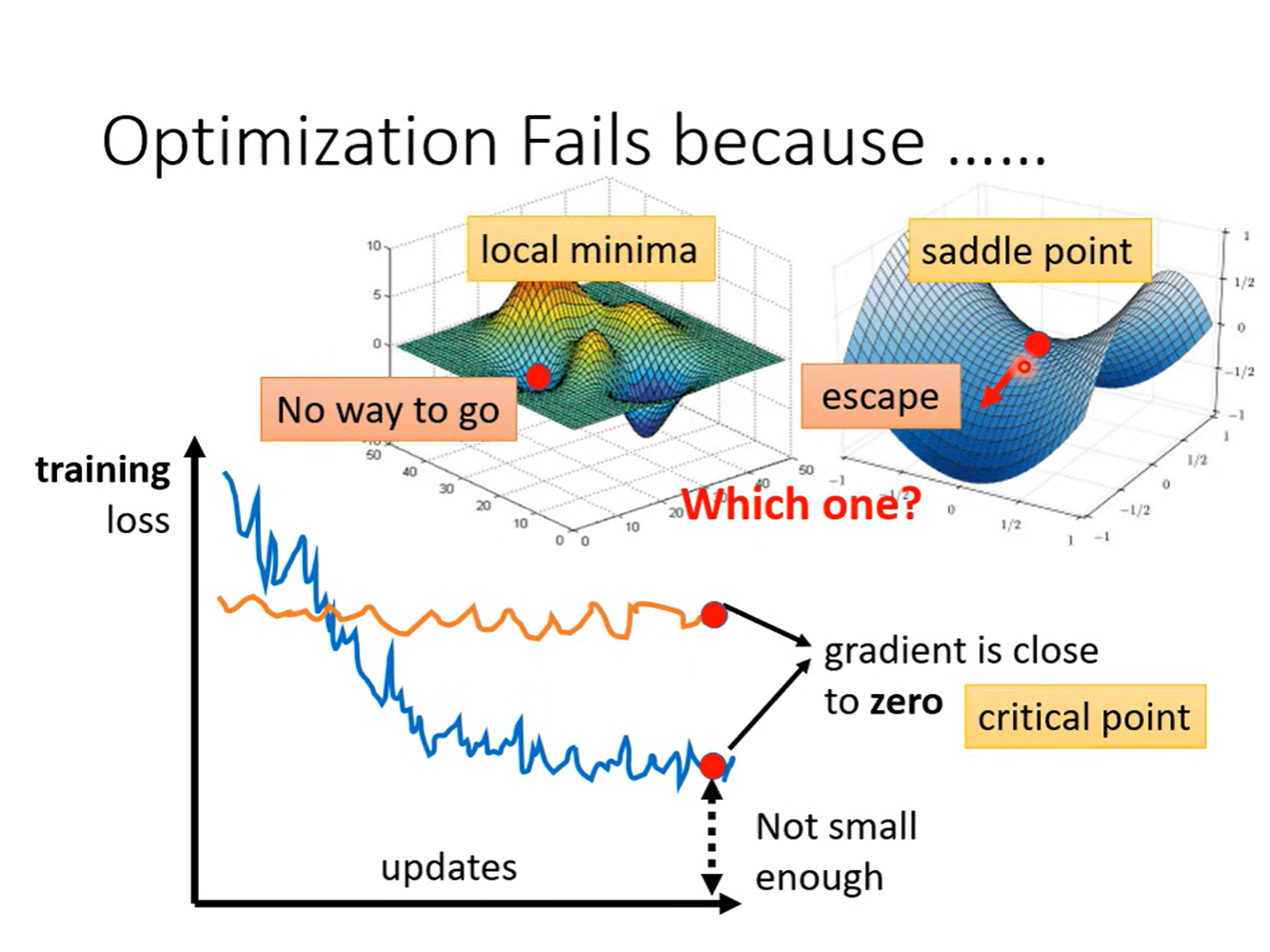
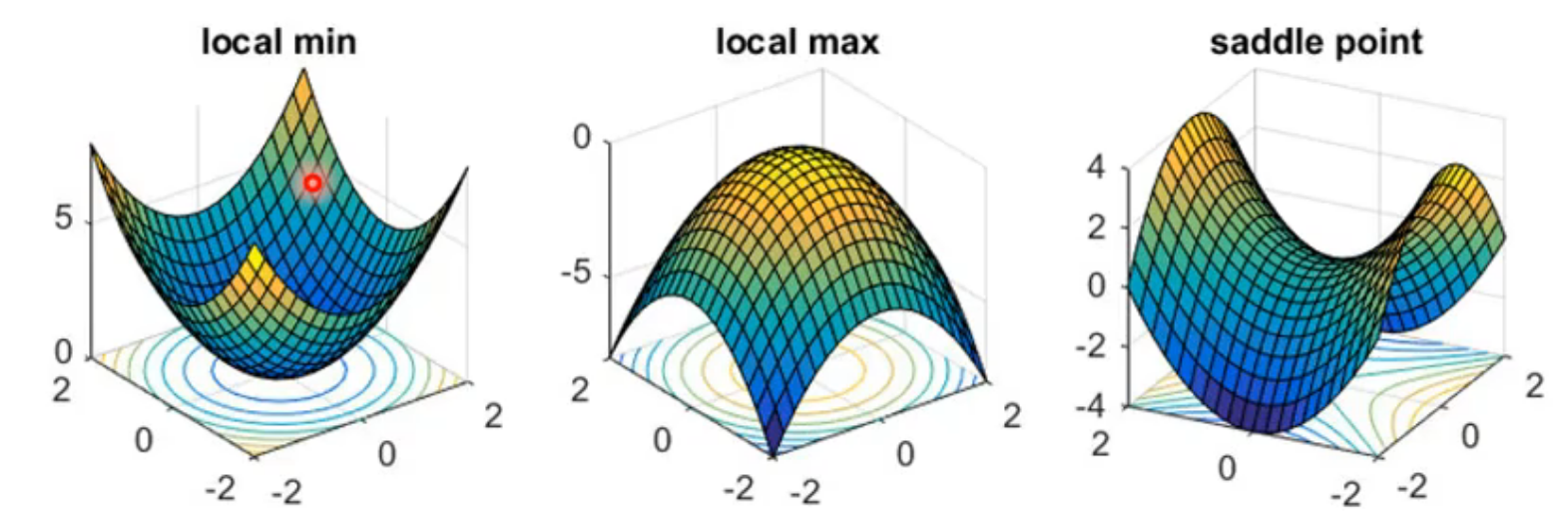
那么当我们遇到梯度为 0 的驻点时,如何判断其是局部最小值点还是导致优化停滞的鞍点呢?此时需要引入 Hessian 矩阵进行判别:
3 Hessian 矩阵与二次型
要判断一个临界点到底是什么,我们需要用到二阶泰勒展开,在临界点 $\theta’$ 附近近似损失函数:
$$
L(\theta) \approx L(\theta’) + \frac{1}{2} (\theta - \theta’)^T H (\theta - \theta’)
$$
这里的 $H$ 就是Hessian 矩阵,是由损失函数 L (θ) 各参数的二阶偏导数构成的对称方阵,用于刻画损失函数曲率,辅助判断驻点类型。
我们设 $v = \theta - \theta’$(移动方向),那么损失的变化就完全由二次项决定:
$$
\Delta L \approx \frac{1}{2} v^T H v
$$
而根据特征向量的定义,对于 Hessian 的特征向量 $u$ 和对应的特征值 $\lambda$,我们有:
$$
u^T H u = \lambda |u|^2
$$
因为 $|u|^2 > 0$,所以 $u^T H u$ 的符号完全由特征值 $\lambda$ 决定:
-
$\lambda > 0$:沿 $u$ 方向走,损失会变大(上坡)。
-
$\lambda < 0$:沿 $u$ 方向走,损失会变小(下坡)。
这就是为什么我们可以用 Hessian 的特征值来判断临界点的类型。
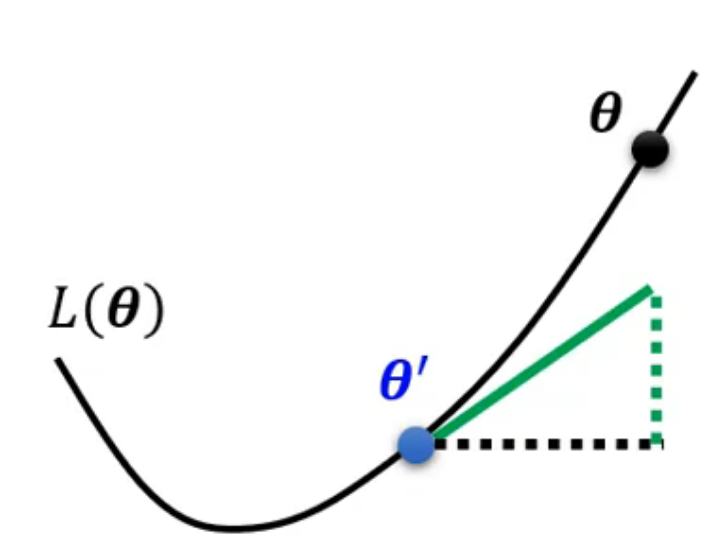
4 收敛点的真实本质
我们可以做一个简单的实验:重复训练同一个网络很多次,每次训练到收敛,然后计算每个临界点 Hessian 矩阵的正特征值比例(我们称之为 Minimum Ratio),并记录对应的训练损失。
我们能从实验结果中清晰地看到一个强规律:
-
左侧点群(Minimum Ratio 很低):损失都很高(0.08-0.09),这些是典型的低维鞍点,有大量负特征值,模型困在这里根本没学好。
-
右侧点群(Minimum Ratio 很高):损失都很低,这些点看起来像“局部极小值”,但它们的 Minimum Ratio 远小于 1,说明 Hessian 矩阵里仍然存在少量负特征值,本质上还是鞍点。
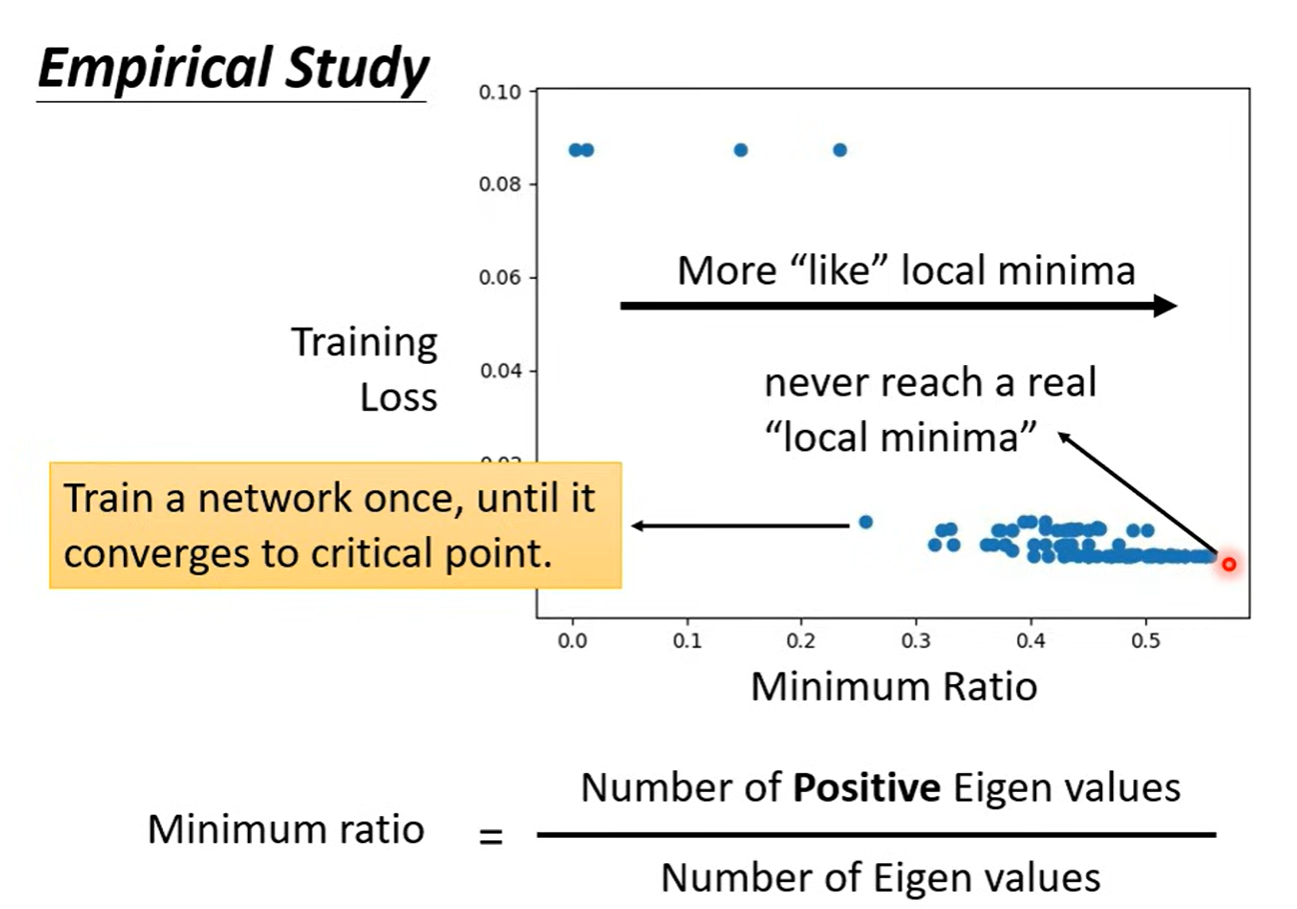
图中的文字 never reach a real "local minima" 直接点破了真相:
我们几乎永远无法到达数学上严格定义的局部极小值,只能停在这些高维鞍点上。
5 总结
-
高维空间中,鞍点数量远多于局部极小值,是模型收敛的主要位置,且鞍点可进一步优化,并非优化终点;
-
驻点类型可通过 Hessian 矩阵特征值判断:所有特征值>0 为局部最小值点,正负特征值共存为鞍点;
-
可沿 Hessian 负特征值对应的特征向量方向,逃离劣质鞍点,继续降低损失;
-
优化的关键并非追求严格局部极小值,而是收敛到负特征值少、正特征值占比偏高的平缓优质临界点,这类点损失更低、泛化性能更好。